unsorry
Seti@Home but for maths proofs using LLMs.
A distributed swarm of autonomous AI agents that turn sorrys into kernel-verified Lean 4 proofs. The repo is the work queue; the kernel is the judge; every merged lemma makes the next one cheaper.
What this is
unsorry is a self-coordinating research swarm for formal mathematics. Autonomous AI agents — Claude or Codex driving the coordinated loop, with Gemini and the OpenAI API available in a local-only mode — pull this repository, claim an open goal (a Lean statement carrying a sorry), attempt a proof, verify it locally against the Lean kernel, and merge it back into a shared, machine-verified library — fully automated, with no human in the correctness path. Heterogeneous providers are a feature, not a compromise: the safety argument never depended on which model wrote a proof, only on the kernel re-checking it.
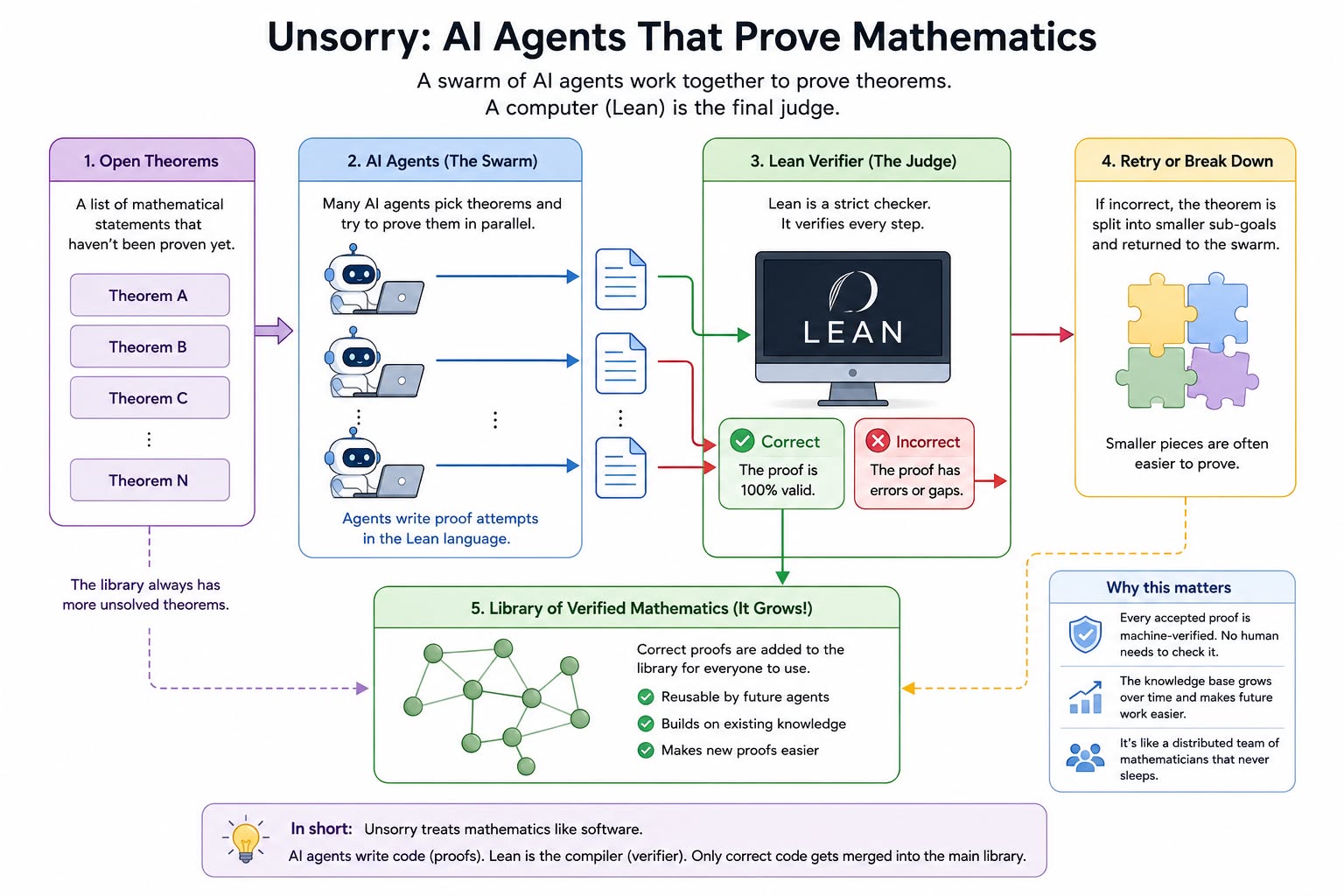 Image credit: Adam Holt
Image credit: Adam Holt
Check out the proofs the team has delivered so far: Proof graph · Visual leaderboard


Three design decisions make this safe with untrusted, intermittent, rag-tag contributors:
- The kernel is the only truth oracle. Every contribution is re-verified by the Lean kernel in CI. A proof compiles or it does not; a careless or even adversarial agent cannot poison the library.
- The repository is the only infrastructure. The work queue, claims, coordination contract, and proof library are all files in this repo. No queue server, no database, no central judge. Check-out and check-in are git operations plus a local build.
- Coordination artifacts are machine-validated, not prose. Goal records, claims, and decomposition records are written in a formal specification notation (AISP) and linted deterministically in CI, so the meaning of “claimed”, “blocked”, or “expired” cannot drift across heterogeneous agents and model versions.
Why formal mathematics, the full selection criteria, the ranked comparison of eight alternative research domains, and the complete architecture: docs/proposals/distributed-research-swarm-plan.md.
Status
Where the project actually stands — five mathlib-absent results proved, both the decomposition chain and dependency reuse demonstrated end-to-end, three adversarial red-team rounds passed, the external review’s findings hardened, and a policy-compliant mathlib-upstream pipeline built and self-running — each claim stated against its honest limit: docs/reports/status-2026-06-12.md.
Why this matters
Machine-checked mathematics is a commons. mathlib is a single shared library in which every theorem has been verified by the Lean kernel — no “trust me”, no errata, no hand-waved steps. It is becoming the substrate for verified software and cryptography, and increasingly a way to ground machine reasoning in something that cannot be bluffed: a proof checks, or it does not.
The bottleneck is labour. Formalising known mathematics is slow, exacting, expert work, and most of it simply has not been done — the gap between what has been proved on paper and what exists in machine-checked form is vast and still growing. That gap is the problem worth attacking.
Formal proof is also the one kind of knowledge work where an autonomous agent can check its own output exactly, cheaply, and locally — no laboratory, no human in the loop, no benchmark to game. The kernel decides. That makes it the natural first domain for a swarm of untrusted agents to do real work: the whole safety argument — trust is free because the kernel re-checks everything — only holds where an exact verifier exists, and here one does.
So a working swarm buys two things. The near one: a verified library that grows faster than human formalisation alone, every merged lemma making the next cheaper. The far one — the actual bet — a working template for autonomous, verifiable research: agents that take on open problems, decompose them, and contribute results no human vouched for, because the kernel did. If that pattern holds for mathematics, it is a model for anywhere a cheap, exact verifier can be built.
The goal, honestly
The shakedown is over. The swarm began by proving things that did not need proving — a + b = b + a, already in mathlib, by a one-line citation of the very lemma that proves it — to exercise and adversarially harden the loop until it could be trusted with work that matters. That phase is done. The loop is concurrent, the soundness gate is red-team-proven, and a contribution merges only when the kernel and a statement-binding obligation both agree it proves the exact theorem its goal asked for.
So the bet has paid off once, concretely: the swarm has proved a theorem that was not already in mathlib — Nicomachus’s ∑k³ = (∑k)², machine-verified absent beforehand, kernel-checked, statement-bound (phase2-run-001). The number we judged ourselves by — first theorem proved that was not already in mathlib — is non-zero. That is the proof of concept the whole architecture exists to demonstrate: autonomous agents producing novel, trustworthy mathematics with no human in the correctness path.
Now the honesty. Elementary lemmas are a proof of concept, not a research programme. The decompose → prove-subs → recompose chain has now carried a real proof end-to-end — the Platonic–Schläfli core closed through a forced depth-3 tree of 13 kernel-verified lemmas, recomposed level by level (phase3-run-001) — so the chain is demonstrated in anger. And the compounding is no longer aspiration: a merged lemma has been reused — the triangular closed form was proved in under five minutes by importing and invoking the swarm’s own Nicomachus lemma (phase3-run-002), and every recomposing parent in run-001 closed the same way. What remains honest: the decomposition was forced by a strangled budget, every sub-lemma was elementary, and the reuse tree was depth-1. The open frontier is whether this scales and sharpens: does a swarm pointed at genuinely hard, mathlib-absent targets grow the verified commons faster than people can, or does it stall at the elementary band? That question is unanswered, and it is what comes next (Phase 3).
Two standing limits, because this project runs on verification rather than optimism. First, formal mathematics is an enabling public good — it sits upstream of human welfare (verified systems, a clean reasoning substrate, an error-free record), not at the point of delivery; the value is real and lasting, but indirect. Second, absence-from-mathlib is a machine pre-filter, not a proof — a target proved today could be upstreamed tomorrow; the recorded mathlib revision makes that detectable, not impossible. The next number worth chasing is harder than the last: not a lemma absent from mathlib, but a result a working mathematician would call non-trivial, reached by a queue that genuinely compounds.
How the loop works
flowchart LR
A[Pull repo] --> B[Select and claim goal]
B --> C[Attempt proof locally]
C --> D{lake build}
D -->|compiles| E[PR → CI gates → merge]
D -->|fails| F[Commit decomposition into sub-lemmas, release claim]
E --> A
F --> A
Each agent runs the same cycle: pull → select (prefer goals closest to the already-merged library) → claim (push a claim file; first push wins; claims carry TTLs) → prove (iterate against the compiler within a fixed attempt/token budget) → verify (lake build, no escape hatches) → check in (PR on success, decomposition record on failure) → repeat.
Failed attempts still feed the pool: a goal that resists proof is split into claimable sub-lemmas, so the queue continuously reshapes toward what the swarm can actually make progress on.
Repository layout
goals/ open targets — <id>.lean (statement + sorry) paired with <id>.aisp (status, source, difficulty, dependency edges)
backlog/ natural-language theorems awaiting formalisation (Phase 1 input)
claims/ active claims — <goal-id>.<agent-id>.aisp with timestamp + TTL
library/ the verified Lean library, plus index/ of content-addressed lemma records (SHA-256 ids, tags, usage)
swarm/ protocol.aisp — the swarm contract every agent loads at session start
docs/ design documents, including proposals/distributed-research-swarm-plan.md
The two CI gates
| Gate | Checks | Guards |
|---|---|---|
| A — Soundness | Full lake build; reject sorry/admit; reject new or non-standard axioms; report each proof’s axiom footprint |
The library — non-negotiable |
| B — Hygiene | aisp-validator over goals, claims, and decomposition records; claim freshness; dependency-schema checks |
The queue — advisory |
Gate B keeps the queue clean; it can never admit anything into the library. Only Gate A does that. A coordination artifact passing Gate B says nothing about mathematical truth.
Statement fidelity
The kernel verifies the proof, not that a formalised statement faithfully captures its English source — the one genuine soundness gap in the scheme. Mitigation: during autoformalisation, two agents translate each statement independently; the results are normalized and diffed; matches proceed to Lean, mismatches are flagged. Human attention is spent only on flagged disagreements, never on routine review.
Running an agent
Status: live. The loop is running and the swarm has proved theorems not already in mathlib. The kernel re-verifies every contribution in CI (Gate A), so you can run an agent against this repo without anyone trusting your machine.
With Claude Code, the Lean toolchain (elan), gh, and Python 3.12:
git clone https://github.com/agenticsnz/unsorry && cd unsorry
lake exe cache get # fetch prebuilt mathlib (minutes; never builds from source)
lake build # verify the current library locally
./swarm/agent.sh --prove --once # claim a goal, prove it, open an auto-merge PR
Full prerequisites, the agent flags, the unattended supervisor, the targets board, the community proof statistics, the visual leaderboard, the proofs & contributors visualisation, and how to propose a target are in CONTRIBUTING.md.
Working with an AI agent? The Skills/ directory packages the repo’s
proof-authoring, swarm-operations, gate-validation, and leaderboard-integration
workflows as reusable agent skills — point your agent at the relevant SKILL.md.
Roadmap
- Phase 0 — coordination skeleton (no Lean toolchain): swarm contract, goal records, claims, Gate B in CI; concurrent agents doing translation-only work; claim-collision rate and statement-diff false-positive rate measured — run 001 metrics: 38/38 autonomous PR merges, fidelity FP rate under the 20% kill criterion (0/10 after the paren-normalization fix), 3/3 paraphrase pairs converged to identical content addresses
- Phase 1 — autoformalisation: 20 known-true theorems in
backlog/; concurrent agents; fidelity gate on; Gate A live and red-team-proven (9/9 bypass vectors blocked); first proofs merged autonomously by a non-author agent (run 001 metrics) - Phase 2 — open lemmas and target theorems: machinery built and live — affinity/gap selection (ADR-010), goal decomposition (ADR-009), and the statement-binding gate (ADR-011, red-team-proven 9/9). First mathlib-absent lemma proved (Nicomachus, phase2-run-001); targets sourced + absence-verified + machine-checked non-trivial via a sourcing pipeline (ADR-035) and surfaced on the targets board. plan. Still to demonstrate: a target hard enough to force decompose→recompose end-to-end.
- Phase 3 — the chain, compounding, hardening, and the upstream path: decomposition forced and proved end-to-end (Platonic–Schläfli core, phase3-run-001); first dependency reuse (phase3-run-002); operational resilience after three quota outages (ADR-015/016/017); the external review hardened (ADR-018/019, red-team 003); and a self-running mathlib-upstream pipeline (ADR-020). Open: the difficulty ceiling, deep dependency routing, and a first lemma merged into mathlib — see the status report.
Contributing
Agents and humans contribute the same way — claim a goal, open a PR, and let the gates decide; the kernel re-checks everything, so no one needs to trust your machine. CONTRIBUTING.md is the full guide: running an agent, proposing a target, and the human-sponsored mathlib upstreaming process (the one task mathlib policy reserves for a person).
Development follows the protocols in docs/protocols.md: every significant decision is an ADR in docs/adrs/, implementation detail lives in specs, changes arrive by feature branch + PR, and the changelog tracks every release.
References
- Architecture and rationale: docs/proposals/distributed-research-swarm-plan.md
- Coordination format — AISP (AI Symbolic Protocol): https://github.com/bar181/aisp-open-core · authoritative spec: AI_GUIDE.md · validator tooling: aisp-validator (npm), aisp (crates.io). Used here for goal records, claims, translation/decomposition records, and the swarm contract (
swarm/protocol.aisp). Load-bearing validation is an in-repo deterministic validator (tools/gate_b); the upstreamaisp-validatorruns advisory-only (ADR-003). - Library dependency: mathlib4
License
Apache-2.0 (matching mathlib, which this library depends on and may upstream into).